
Menu
Yesterday I updated the Complexity domain model, but left the coherence diagonal for today. I promised to do this in the context of Agile, Scrum, KANBAN and the like and will do so, although the points are more generally applicable. I also want to make an important qualification before moving forward. I know that many Agile practitioners have intuited some of what I am going to talk about, and some have moved onto action. There are elements of Chris Matts real option theory that I could have more directly referenced for example – not the same thing but similar.
I had already opened my keynote yesterday with a reference to the dangers of using manufacturing models for all aspects of software delivery. Given the desire to move manufacturing models across, explicitly in the case of KANBAN and SCRUM, this means I am running against the norm a little but less than you might think. Whether you put things on cards and move them around between columns or take the Product Owner's specification (the use of 'Product' gives things away) you are assuming a degree of definition and agreement that places the requirement in the central box of my complexity three by three. As the sprints progress through linear iterations then the results are realised by a “self-organising” managed by the SCRUM Master, they are operationalised in varying degrees and shift into the complicated domain. They move from exploration to exploitation and SCRUM, properly understood is a means of moving something from the complex to the complicated domain. KANBAN can be used in any Cynefin domain, but has to be used differently – I will save that for another day.
The sprint allows for iterations and changes and is exploratory in nature, but it is constrained by the teams commitments, the nature of the backlog, the project managers, stakeholders and the like. All in all the language, construct, metaphors and process is a manufacturing one. The granularity of the requirement also has to be of sufficient size to justify its entry into the process in the first place.
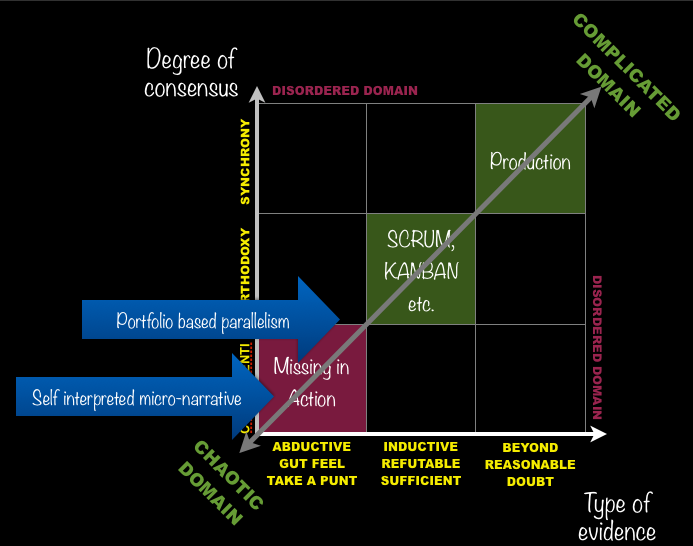 Now all of that is well and good, but what we are missing is the bottom left, high exploratory, edge of chaos state in which there are many competing hypotheses all of which have similar levels of coherence. They may be very finely grained, contradictory and often unarticulated.
Now all of that is well and good, but what we are missing is the bottom left, high exploratory, edge of chaos state in which there are many competing hypotheses all of which have similar levels of coherence. They may be very finely grained, contradictory and often unarticulated.
Now this is where two different sets of Cognitive Edge capability come into play.
Firstly one of the basic switches is from serial iterations to parallel safe-to-fail experiments. They may not be big enough for a conventional sprint, although I think there is some work to be done here on a mini-SCRUM (tag rugby metaphors are coming to mind). There are some basic principles that apply to those experiments.
One big plus point with this parallel and portfolio type approach is that senior funders will grant that some should be high risk, high return. They understand portfolios its a pattern so play to it.
Secondly and critically is the new work we are using to create a version of SenseMaker® that will capture user requirements not as a response to a question about a product they might want, but as the fragmented day to day experiences, frustrations and desires of user lives over time. As patterns form (in SenseMaker® through the human metadata approach statistically) those cluster patterns can become 'products' in the mini-sprint situation or even a full sprint. You can even write them on the cards. Leave the system in place and you can measure impact of development. Software to my mind should be measured by how it changes user stories, not on satisfying a product or requirements definition.
I will write a lot more on that second one as we progress to a launch shortly, but the principle is there for now. Anyone who wants to know more can come on the new Cynefin training programmes where the domain models are now taught and there is a whole day on the use of SenseMaker®. The next one is in San Francisco, followed by London and Melbourne.
And just to repeat, this post represents a continuation of early thinking. More to do, more to listen to, more to say, more to write.



Cognitive Edge Ltd. & Cognitive Edge Pte. trading as The Cynefin Company and The Cynefin Centre.
© COPYRIGHT 2024

I've fallen behind on this blog over the last week and I have some backfill ...
My original plan for yesterday was to spend the day walking around Krackow with the ...